[DeepLearning] CH04. 머신 러닝의 기본 요소(2)
in Deep Learning on Deeplearning
케라스 창시자에게 배우는 딥러닝을 기반으로 공부한 내용을 정리합니다.

4.2 머신 러닝 모델 평가
지금까지 데이터를 훈련 세트, 검증 세트, 테스트 세트로 나누어왔습니다. 훈련에 사용된 동일한 데이터로 모델을 평가하지 않는 이유는 몇 번의 에포크 이후 모델이 과대적합되기 시작해서 입니다.
즉 훈련 데이터의 성능에 비해 처음 본 데이터에 대한 성능이 좋아지지 않습니다(또는 더 나빠집니다). 반면에 훈련 데이터의 성능은 훈련이 진행될수록 항상 증가됩니다.
머신 러닝의 목표는 처음 본 데이터에서 잘 작동하는 일반화된 모델을 얻는 것입니다.
과대적합은 주요 장애물입니다. 관측할 수 있는 것만 제어할 수 있으므로 모델의 일반화 성능에 대한 신뢰할 수 있는 측정 방법이 아주 중요합니다.
4.2.1 훈련, 검증, 테스트 세트
모델 평가의 핵심은 가용한 데이터를 항상 trian, validation, test 3개의 set으로 나누는 것입니다.
훈련 세트에서 모델을 훈련하고 검증 세트에서 모델을 evaluate합니다. 모델을 출시할 준비가 되면 테스트 세트에서 최종적으로 딱 한 번 모델을 테스트합니다.
훈련 세트와 테스트 세트 2개만 사용하지 않는 이유는 모델을 개발할 때 항상 모델의 설정을 튜닝하기 때문입니다.
예를 들어 층의 수나 층의 유닛 수를 선택합니다 (이런 parameter를 네트워크의 가중치와 구분하기 위해 하이퍼파라미터(hyperparameter)라고 부릅니다).
검증 세트에서 모델의 성능을 평가하여 이런 튜닝을 수행합니다.
본질적으로 튜닝도 어떤 파라미터 공간에서 좋은 설정을 찾는 학습입니다.
결국 검증 세트의 성능을 기반으로 모델의 설정을 튜닝하면 검증 세트로 모델을 직접 훈련하지 않더라도 빠르게 검증 세트에 과대적합될 수 있습니다.
이 현상의 핵심은 정보 누설(information leak) 개념에 있습니다.
검증 세트의 모델 성능에 기반하여 모델의 하이퍼파라미터를 조정할 때마다 검증 데이터에 관한 정보가 모델로 새는 것입니다. 하나의 파라미터에 대해서 단 한 번만 튜닝한다면 아주 적은 정보가 누설됩니다. 이런 검증 세트로는 모델을 평가할 만합니다.
하지만 한 번 튜닝하고 나서 검증 세트에 평가한 결과를 가지고 다시 모델을 조정하는 과정을 여러 번 반복하면, 검증 세트에 관한 정보를 모델에 아주 많이 노출시키게 됩니다.
결국 검증 데이터에 맞추어 최적화했기 때문에 검증 데이터에 의도적으로 잘 수행되는 모델이 만들어집니다.
모델을 평가하기 위해 이전에 본 적 없는 완전히 다른 데이터셋인 테스트 세트를 사용해야 합니다.
모델은 간접적으로라도 테스트 세트에 대한 어떤 정보도 얻어서는 안됩니다. 테스트 세트 성능에 기초하여 튜닝한 모델의 모든 설정은 일반화 성능을 왜곡시킬 것입니다.
데이터를 훈련, 검증, 테스트 세트로 나누는 고급 기법이 있습니다.
- 단순 홀드아웃 검증(hold-out validation)
데이터의 일정량을 테스트 세트로 슬라이싱 합니다. 남은 데이터에서 훈련하고 테스트 세트로 평가합니다.
또한 정보 누설을 막기 위해 테스트 세트를 사용하여 모델을 튜닝하면 안되기 때문에 검증 세트도 따로 슬라이싱 해줘야 합니다.
# code 4-1 홀드아웃 검증 구현 예
num_validation_samples = 10000
np.random.shuffle(data) # 데이터를 섞는 것이 좋습니다.
validation_data = data[:num_validation_samples] # 검증 세트 생성
data = data[num_validation_samples:]
training_data = data[:] # 훈련 세트 생성
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data) # 훈련세트에서 모델 훈련, 검증 세트로 평가
# 모델 튜닝 -> 훈련 -> 평가 -> 다시 튜닝 (반복)
model = get.model()
model.train(np.concatenate([training_data, validation_data]))
test_score = model.evaluate(test_data)
# 하이퍼파라미터 튜닝이 끝나면, 테스트 데이터를 제외한 모든 데이터를 사용하여 모델을 다시 훈련시킵니다.
이 평가 방법은 데이터가 적을 때 검증 세트와 테스트 세트의 샘플이 너무 적어 주어진 전체 데이터를 통계적으로 대표하지 못할 수 있습니다.
다른 난수 초깃값으로 shuffling해서 데이터를 나누었을 때 모델의 성능의 편차가 크면 문제가 있는 것으로 알 수 있습니다.
하지만 K-겹 교차 검증과 반복 K-겹 교차 검증이 위 문제를 해결할 수 있습니다.
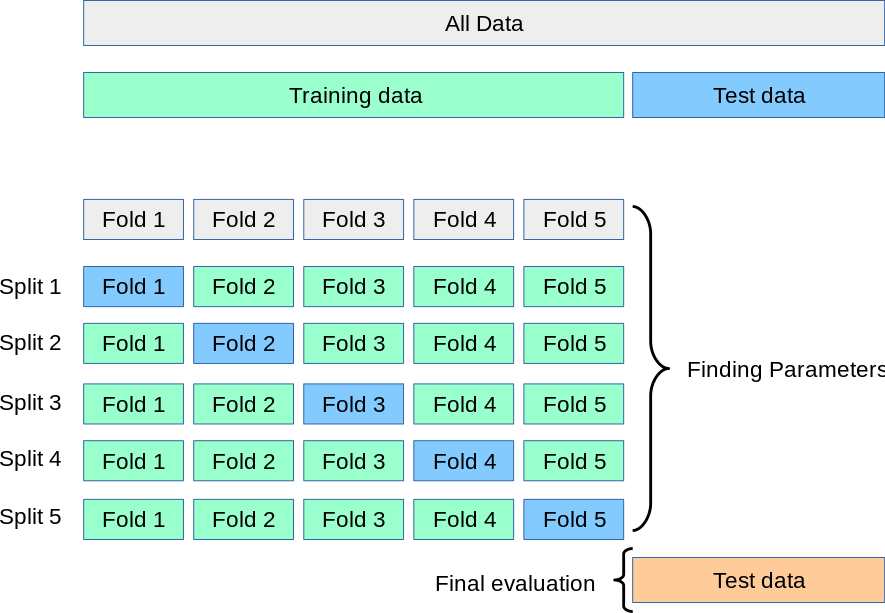
- K-겹 교차검증
(1) 데이터를 동일한 크기를 가진 K개 분할로 나눕니다.
(2) 각 분할 i에 대해 남은 K-1개의 분할로 모델을 훈련하고 분할 i에서 모델을 평가합니다.
(3) 최종 점수는 이렇게 얻은 K개의 점수를 평균합니다.
이 방법은 모델의 성능이 데이터 분할에 따라 편차가 클 때 도움이 됩니다. 마찬가지로 모델의 튜닝에 검증 세트를 사용하게 됩니다.
# code 4-2 K-겹 교차 검증 구현 예
k = 4
num_validation_samples = len(data) // 4
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
validation_data = data[num_validation_samples * fold:num_validation_samples * (fold + 1)]
# 검증 데이터 부분 선택
training_data = data[:num_validation_samples * fold] + data[num_validation_samples * (fold + 1):]
# 남은 데이터를 훈련 데이터로 사용
# 리스트에서 + 연산자는 두 리스트를 연결하는 것입니다.
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)validation_scores.append(validation_score)
validation_score = np.average(validation_scores)
# 검증 점수: K개 fold의 검증 점수 평균
model = get_model()
model.train(data)
test_score = model.evaluate(test_data)
# 테스트 데이터를 제외한 전체 데이터로 최종 모델을 훈련합니다.
- 셔플링을 사용한 반복 K-겹 교차 검증
이 방법은 비교적 가용 데이터가 적고 가능한 정확하게 모델을 평가하고자 할 때 사용합니다.
K-겹 교차 검증을 여러 번 적용하되 K개의 분할로 나누기 전에 매번 데이터를 무작위로 섞습니다. 최종 점수는 모든 K-겹 교차 검증을 실행해서 얻은 점수의 평균이 됩니다.
결국 P * K개(P는 반복횟수)의 모델을 훈련하고 평가하므로 비용이 매우 많이 듭니다.
4.2.2 기억해야 할 것
평가 방식을 선택할 때 다음 사항을 유념해야 합니다.
대표성 있는 데이터: 훈련 세트와 테스트 세트가 주어진 데이터에 대한 대표성이 있어야 합니다. 예를 들어 숫자 이미지를 분류하는 문제에서 샘플 배열이 클래스 순서대로 나열되어 있다고 가정하겠습니다. 이 배열의 처음 80%를 훈련 세트로 나머지 20%를 테스트 세트로 만들면 훈련 세트에는 0~7 숫자만 담겨 있고 테스트 세트는 8~9 숫자만 담기게 됩니다. 이런 이유 때문에 trian set와 test set으로 나누기 전에 데이터를 무작위로 섞는 것이 일반적입니다.
시간의 방향: 과거로부터 미래를 예측하려면(ex. 내일 날씨, 주식 시세 등) 데이터를 분할하기 전에 무작위로 섞어서는 안됩니다. 미래의 정보가 누설되기 때문입니다. 즉 모델이 사실상 미래 데이터에서 훈련될 것입니다. 다시 말해, 테스트 세트에 있는 모든 데이터가 미래의 것이어야 합니다.
데이터 중복: 한 데이터셋에 어떤 데이터 포인트가 두 번 등장하면, 데이터를 섞고 훈련 세트와 검증 세트로 나누었을 때 훈련 세트와 검증 세트에 데이터 포인트가 중복될 수 있습니다. 이로 인해 훈련 데이터의 일부로 테스트하는 최악의 경우가 발생할 수 있습니다.
Reference
- 케라스 창시자에게 배우는 딥러닝
- https://scikit-learn.org/stable/modules/cross_validation.html
