[DeepLearning] CH03. 신경망 시작하기(3)
in Deep Learning on Deeplearning
케라스 창시자에게 배우는 딥러닝을 기반으로 공부한 내용을 정리합니다.

3.5 뉴스 기사 분류: 다중 분류 문제
이번 장에서는 로이터(Reuter) 뉴스를 46개의 상호 배타적인 토픽으로 분류하는 신경망을 만들어 보겠습니다. 클래스가 많기 때문에 이 문제는 다중 분류(multiclass classification)의 예입니다.
3.5.1 로이터 데이터셋
짧은 뉴스 기사와 토픽의 집합인 로이터 데이터셋은 텍스트 분류를 위해 널리 사용되는 간단한 데이터 셋입니다. 46개의 토픽이 있으며 각 토픽은 훈련 세트에 최소한 10개의 샘플을 가지고 있습니다.
# code 3-12 Reuter DataSet Load
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words = 10000)
>>> len(train_data)
8982
>>> len(test_data)
2246
3.5.2 데이터 준비
먼저 데이터를 벡터로 변환합니다.
# code 3-14 데이터 인코딩하기
import numpy as np
def vectorize_sequence(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
레이블을 벡터로 바꾸는 방법으로 레이블의 리스트를 정수 텐서로 변환하는 법과 one-hot 인코딩을 사용하는 것이 있습니다. one-hot 인코딩은 범주형 데이터에서 널리 사용되며 범주형 인코딩(categorical encoding)이라고도 부릅니다.
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
사실 케라스에는 범주형 데이터를 인코딩해주는 내장 함수가 있습니다.
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
3.5.3 모델 구성
Dense 층을 쌓으면 각 층은 이전 층의 출력에서 제공한 정보만 사용할 수 있습니다. 만약 한 층이 문제 해결에 필요한 일부 정보를 누락하면 그 다음 층에서 이를 복원할 방법이 없습니다.
이전 예제와 같이 16차원을 가진 중간층을 사용하면 지금처럼 46개의 클래스를 구분하기엔 제약이 많을 것으로 예상되며, 이렇게 될 경우 작은 층은 유용한 정보를 잃게되는 정보의 병목 지점처럼 동작할 수 있습니다. 따라서 64개의 유닛을 사용해 규모가 큰 층을 사용하겠습니다.
# code 3-15 모델 정의하기
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
- 마지막 Dense 층의 크기가 46인 것은 각 입력 샘플에 대해서 46차원의 벡터를 출력한다는 뜻입니다.
- softmax 활성화 함수를 통해 각 입력 샘플마다 46개의 출력 클래스에 대한 확률 분포를 출력합니다. 즉 output[i]는 어떤 샘플이 클래스 i에 속할 확률입니다. 46개의 값을 모두 더하면 1이 됩니다.
그리고 이런 다중 분류 문제에 사용할 최선의 손실 함수는 categorical_crossentropy입니다. 이 함수는 두 확률 분포 사이의 거리를 측정합니다. 네트워크가 출력한 확률 분포와 진짜 레이블의 분포 사이의 거리입니다. 두 분포 사이의 거리를 최소화하면 진짜 레이블에 가능한 가까운 출력을 내도록 모델을 훈련하게 됩니다.
# code 3-16 model compile
model.compile(optimizer='rmsprop',
loss = 'categorical_crossentropy',
metrics=['accuracy'])
3.5.4 훈련 검증
훈련 데이터에서 1,000개의 샘플을 슬라이싱하여 validation set로 사용하겠습니다.
# code 3-17 검증 세트 준비하기
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
이제 모델을 훈련시켜줍니다.
# code 3-18 모델 훈련하기
history = model.fit(partial_x_train,
partial_y_train,
epochs = 20,
batch_size=512,
validation_data=(x_val, y_val))
마지막으로 손실과 정확도 곡선을 그립니다.
# code 3-19 훈련과 검증 손실 그리기
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
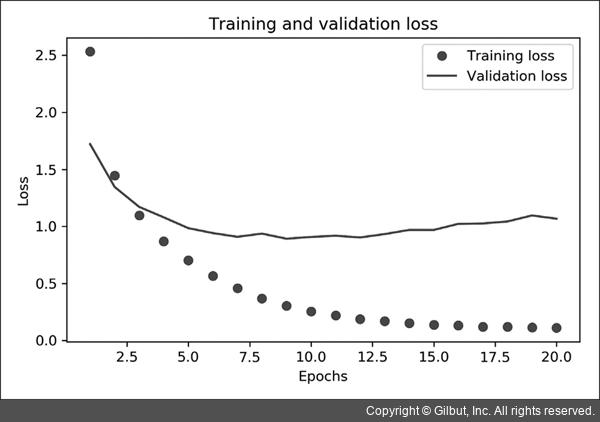 훈련과 검증 손실
훈련과 검증 손실
# code 3-20 훈련과 검증 정확도 그리기
plt.clf() # 그래프 초기화
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(epochs, acc, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
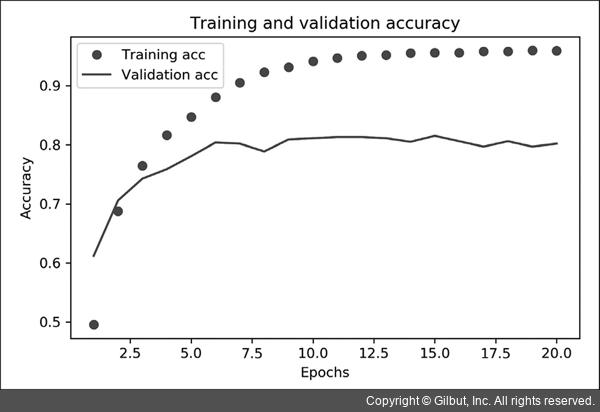 이 모델은 아홉 번째 에포크 이후에 overfitting이 시작됩니다.
이 모델은 아홉 번째 에포크 이후에 overfitting이 시작됩니다.
이번에도 아홉 번의 에포크로 새로운 모델을 훈련하고 테스트 세트에서 평가하겠습니다.
# code 3-21 모델을 처음부터 다시 훈련하기
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels))
# 최종 결과입니다.
>>> results
[1.0224982575, 0.77560106]
대략 78%의 정확도를 달성했습니다.
3.5.5 새로운 데이터에 대해 예측하기
모델 객체의 predict 메소드는 46개의 토픽에 대한 확률 분포를 리턴합니다. 테스트 데이터 전체에 대한 토픽을 예측해 보겠습니다.
# code 3-22 새로운 데이터에 대해 예측하기
predictions = model.predict(x_test) # 길이가 46인 벡터
>>> predictions[0].shape
(46,)
>>> np.sum(predictions[0]) # 확률이므로 모든 원소 합은 1
1.0
>>> np.argmax(predictions[0])
3
3.5.6 레이블과 손실을 다루는 다른 방법
레이블을 인코딩하는 다른 방법은 바로 정수 텐서로 변환하는 것입니다.
y_train = np.array(train_labels)
y_test = np.array(test_labels)
이 방식을 사용하려면 손실 함수 하나만 바꾸면 됩니다.
categorical_crossentropy는 레이블이 범주형 인코딩되어 있을 때 사용합니다. 정수 레이블을 사용할 때는 sparse_categorical_crossentropy를 사용해야 합니다.
3.5.7 충분히 큰 중간층을 두어야 하는 이유
이 장에서 생성한 모델은 마지막 출력이 46차원이기 때문에 중간층의 hidden unit이 46개보다 많이 적으면 안됩니다.
46차원보다 훨씬 작은 중간층을 두면 정보의 병목이 어떻게 나타날까요?
검증 정확도의 최고 값은 약 71%로 이전보다 8% 정도 감소되었습니다.
이런 손실의 원인은 많은 정보를 중간층의 저차원 표현 공간으로 압축하려고 했기 때문입니다.
3.5.8 추가 실험
- 더 크거나 작은 층을 사용하기(32개 unit, 128개 unit)
32개 unit 손실: 1.1000070571899414
32개 unit 정확도: 0.7493321299552917
128개 unit 손실: 1.0402452945709229
128개 unit 정확도: 0.7956367135047913 - 1개 또는 3개의 hidden layers 사용하기
1개 사용했을 때 손실: 1.1150789260864258
1개 사용했을 때 정확도: 0.7715939283370972
3개 사용했을 때 손실: 0.917966365814209
3개 사용했을 때 정확도: 0.7965271472930908
3.5.9 정리
- N개의 클래스로 데이터 포인트를 분류하려면 네트워크의 마지막 Dense 층의 크기는 N이어야 합니다.
- 단일 레이블, 다중 분류 문제에서는 N개의 클래스에 대한 확률 분포를 출력하기 위해 softmax 활성화 함수를 사용해야 합니다.
- 이번 장과 같은 문제에서는 항상 범주형 cross_entropy를 사용해야 합니다. 이 함수는 모델이 출력한 확률 분포와 타깃 분포 사이의 거리를 최소화합니다.
- 다중 분류에서 레이블을 다루는 두 가지 방법
- 레이블을 범주형 인코딩(또는 one-hot 인코딩)으로 인코딩하고 categorical_crossentropy 손실 함수를 사용합니다.
- 레이블을 정수로 인코딩하고 sparse_categorical_crossentropy 손실 함수를 사용합니다.
- 많은 수의 범주를 분류할 때 중간층의 크기가 너무 작아 네트워크에 정보의 병목이 생기지 않도록 해야 합니다.
Reference
- 케라스 창시자에게 배우는 딥러닝
- https://wikidocs.net/35476
- https://m.blog.naver.com/wideeyed/221021710286
