[DeepLearning] CH03. 신경망 시작하기(2)
in Deep Learning on Deeplearning
케라스 창시자에게 배우는 딥러닝을 기반으로 공부한 내용을 정리합니다.

3.4 영화 리뷰 분류: 이진 분류 예제
이번 장에서는 리뷰 텍스트를 기반으로 영화 리뷰를 긍정(positive)과 부정(negative)으로 분류하는 방법을 배우겠습니다.
3.4.1 IMDB 데이터 셋
Internet Movie Database로부터 가져온 리뷰 5만 개로 이루어진 IMDB 데이터셋을 사용하겠습니다. 훈련 데이터 2만 5,000개와 테스트 데이터 2만 5,000개로 나뉘어 있고 각각 50%는 부정, 50%는 긍정 리뷰로 구성되어 있습니다.
훈련 데이터와 테스트 데이터로 나누는 이유는 같은 데이터에서 머신 러닝 모델을 훈련하고 테스트해서는 절대 안되기 때문입니다. 훈련 데이터에서 잘 작동하는 것도 중요하지만 그보다 더 중요한 것은 새로운 데이터에 대한 모델의 성능입니다.
IMDB 데이터는 전처리되어 있어 각 리뷰(단어 시퀀스)가 숫자 시퀀스로 변환되어 있습니다. 여기서 각 숫자는 사전에 있는 고유한 단어를 나타냅니다.
먼저 데이터셋을 로드합니다.
# code 3-1 IMDB Dataset Load
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = 10000)
num_words = 10000 매개변수는 훈련 데이터에서 가장 자주 나타나는 단어 1만 개만 사용하겠다는 뜻입니다.
변수 train_data와 test_data는 리뷰의 목록입니다. 각 리뷰는 단어 인덱스의 리스트입니다(단어 시퀀스가 인코딩된 것입니다). train_labels와 test_labels는 부정을 나타내는 0과 긍정을 나타내는 1의 리스트입니다.
>>> train_data[0]
[1, 14, 22, 16, ..., 178, 32]
>>> train_labels[0]
1
가장 자주 등장하는 단어 1만 개로 제한했기 때문에 단어 인덱스는 9,999를 넘지 않습니다.
>>> max([max(sequence) for sequence in train_data])
9999
리뷰 데이터를 원래 영어 단어로 바꾸는 방법입니다.
word_index = imdb.get_word_index()
# {'bettina': 25184, "'cannes'": 70227, 'karel': 87565, 'heorot': 30490, 'karen': 4112, "1992's": 34683, 'snorer': 34586, [생략] }
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) # 정수 인덱스와 단어를 매핑하도록 뒤집어줍니다.
# {25184: 'bettina', 70227: "'cannes'", 87565: 'karel', 30490: 'heorot', 4112: 'karen', 34683: "1992's", 34586: 'snorer', [생략] }
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
# ? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as [생략]
items() 는 dictionary의 key와 value를 list로 반환을 하고, value와 key 값을 뒤집어줘서 dict 형식으로 반환합니다.
imdb.get_word_index()에 각 단어와 맵핑되는 정수가 저장되어져 있습니다. 주의할 점은 imdb.get_word_index()에 저장된 값에 +3을 해야 실제 맵핑되는 정수입니다. 이것은 IMDB 리뷰 데이터셋에서 정한 규칙입니다.
이제 리뷰를 디코딩 하는 작업입니다. train_data를 디코딩하는데 get()은 key값을 통해 value를 찾아주고 못찾은 경우에는 ‘?’로 대체합니다.
이 작업이 필요한 이유는 위에서 데이터를 받아올 때 num_words=10000 을 통해 만 개의 자주 쓰이는 단어만 가져왔으므로 나머지 단어에 대해서는 값이 존재하지 않으므로 다음 작업이 필요합니다.
그리고 각 단어를 join() 을 통해서 공백으로 이어주었습니다. IMDB 리뷰 데이터셋에서는 0, 1, 2는 특별 토큰이며, 해당하는 값은 ‘패딩’, ‘문서 시작’, ‘사전에 없음’ 을 위함이므로 3을 빼고 계산합니다.
3.4.2 데이터 준비
신경망에 숫자 리스트를 주입할 수는 없습니다. 리스트를 텐서로 바꿔줘야 합니다.
같은 길이가 되도록 리스트에 패딩(padding)을 추가하고 (samples, sequence_length) 크기의 정수 텐서로 변환합니다. 그 다음 이 정수 텐서를 다룰 수 있는 층을 신경망의 첫 번째 층으로 사용합니다(Embedding 층을 말합니다).
리스트를 one-hot encoding하여 0과 1의 벡터로 변환합니다. 예를 들어 시퀀스 [3, 5]를 인덱스 3과 5의 위치는 1이고 그 외는 모두 0인 10,000차원의 벡터로 각각 변환합니다. 그 다음 부동 소수 벡터 데이터를 다룰 수 있는 Dense 층을 신경망의 첫 번째 층으로 사용합니다.
리스트가 하나의 벡터로 변환되므로 훈련 데이터를 변환한 텐서의 크기는 (25000, 10000)이 됩니다.
# code 3-2 정수 시퀀스를 이진 행렬로 인코딩하기
import numpy as np
def vectorize_sequence(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension)) # len(sequences) * 10000 크기의 모든 성분이 0인 2차원 넘파이 배열 생성
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # i번째 행에 sequence 리스트의 원소에 접근 후 그 자리에만 1을 대입
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
이제 샘플은 다음과 같이 나타납니다.
>>> x_trian[0]
array([0., 1., 1., ..., 0., 0., 0.])
레이블을 벡터로 바꾸는 방법입니다.
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
이제 신경망에 주입할 데이터가 준비되었습니다!
3.4.3 신경망 모델 만들기
Input data가 벡터고 label은 스칼라(1 or 0)입니다. 이런 문제에서 가장 적합한 네트워크 종류는 relu 활성화 함수를 사용한 fully connected layer(즉 Dense(16, activation='relu'))을 그냥 쌓은 것입니다.
Dense 층에 전달한 매개변수(16)는 은닉 유닛(hidden unit)의 개수입니다. 하나의 hidden unit은 층이 나타내는 표현 공간에서 하나의 차원이 됩니다.
output = relu(dot(W, input) + b)
16개의 hidden unit이 있다는 것은 가중치 행렬 W의 크기가 (input_dimension, 16)이라는 뜻입니다. Input data와 W를 점곱하면 Input data가 16차원으로 표현된 공간으로 투영됩니다. (그리고 편향 벡터 b를 더하고 relu 연산을 적용합니다).
hidden unit을 늘리면(표현 공간을 더 고차원으로 만들면) 신경망이 더욱 복잡한 표현을 학습할 수 있지만 계산 비용이 커지고 원하지 않는 패턴을 학습할 수도 있습니다 (훈련 데이터에서는 성능이 향상되지만 테스트 데이터에서는 그렇지 않은 패턴).
Dense 층을 쌓을 때 두 가지 중요한 구조상의 결정이 필요합니다.
- 얼마나 많은 층을 사용할 것인가?
- 각 층에 얼마나 많은 은닉 유닛을 둘 것인가?
ch04에서 이런 결정을 하는데 도움이 되는 원리를 배울 예정입니다. 당분간은 아래와 같은 구조를 사용하겠습니다.
- 16개의 hidden unit을 가진 2개의 hidden layer
- 현재 리뷰의 감정을 스칼라 값의 예측으로 출력하는 세 번째 층
중간에 있는 hidden layer는 활성화 함수로 relu를 사용하고 마지막 층은 확률(0과 1사이의 점수)을 출력하기 위해 sigmoid 활성화 함수를 사용합니다.
relu는 입력값이 0보다 작으면(음수이면) 0이고, 0보다 크면 입력값 그대로 출력합니다.
sigmoid는 임의의 값을 [0, 1] 사이로 압축하므로 출력 값을 확률처럼 해석할 수 있습니다.
# code 3-3 모델 정의하기
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
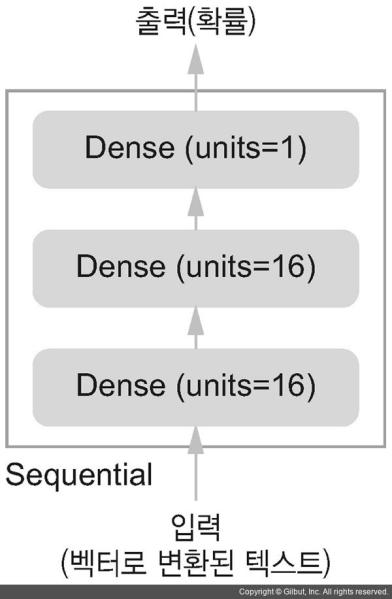
3개의 층으로 된 신경망
활성화 함수가 필요한 이유
relu와 같은 활성화 함수(또는 비선형성(non-linearity))가 없다면 Dense 층은 선형적인 연산인 점곱과 덧셈 2개로 구성됩니다.
output = dot(W, input) + b
그러므로 이 층은 선형 변환만을 학습할 수 있습니다. 선형 층을 깊게 쌓아도 여전히 하나의 선형 연산이기 때문에 층을 여러 개로 구성하는 장점이 없습니다. 즉 층을 추가해도 가설 공간이 확장되지 않습니다.
따라서 가설 공간을 풍부하게 만들어 층을 깊게 만드는 장점을 살리기 위해서 비선형성 또는 활성화 함수를 추가해야 합니다.
마지막으로 손실 함수와 옵티마이저를 선택해야 합니다. 이진 분류 문제고 신경망의 출력이 확률이기 때문에 binary_crossentropy 손실이 적합합니다.
그 밖에 mean_squared_error(mse)도 사용할 수 있습니다(회귀 문제에 사용되는 대표적인 손실 함수). 확률을 출력하는 모델을 사용할 때는 crossentropy가 가장 적합합니다(확률 분포 간의 차이를 측정).
# code 3-4 model compile
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
케라스에 rmsprop, binary_crossentropy, accuracy가 포함되어 있기 때문에 옵티마이저, 손실 함수, 측정 지표를 문자열로 지정하는 것이 가능합니다.
간혹 옵티마이저의 매개변수를 바꾸거나 자신만의 손실 함수, 측정 함수를 전달해야 할 경우가 있습니다.
# code 3-5 optimizer 설정하기
# 객체 직접 생성해 optimizer 매개변수에 전달
from keras import optimizers
model.compile(optimizer = optimizers.RMSprop(lr=0.001),
loss = 'binary_crossentropy',
metrics = ['accuracy'])
# code 3-6 손실과 측정을 함수 객체로 지정하기
# loss와 metrics 매개변수에 함수 객체 전달
from keras import losses
from keras improt metrics
model.compile(optimizer = optimizers.RMSprop(lr=0.001),
loss = losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
3.4.4 훈련 검증
처음 본 데이터에 대한 모델의 정확도를 측정하기 위해서 원본 훈련 데이터에서 10,000의 샘플을 떼어 검증 세트를 만들어야 합니다.
# code 3-7 validation_data
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
이제 모델을 512개의 샘플씩 mini-batch를 만들어 20번의 epoch 동안 훈련시킵니다(x_train과 y_train 텐서에 있는 모든 샘플에 대해 20번 반복합니다). 동시에 슬라이싱한 1만 개의 샘플에서 손실과 정확도를 측정하겠습니다. 이를 위해 validation_data 매개변수에 검증 데이터를 전달해야 합니다.
# code 3-8 모델 훈련하기
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics=['acc'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
history 객체는 훈련하는 동안 발생한 모든 정보를 담고 있는 딕셔너리인 history 속성을 가지고 있습니다.
>>> history_dict = history.history
>>> history_dict.keys()
[u'accuracy', u'loss', u'val_accuracy', u'val_loss']
다음으로 train과 validation 데이터에 대한 손실과 정확도를 그려보겠습니다.
# code 3-9 훈련과 검증 손실 그리기
import matplotlib.pyplot as plt
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss') # 'bo'는 파란색 점을 의미
plt.plot(epochs, val_loss, 'b', label='Validation loss') # 'b'는 파란색 실선을 의미
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
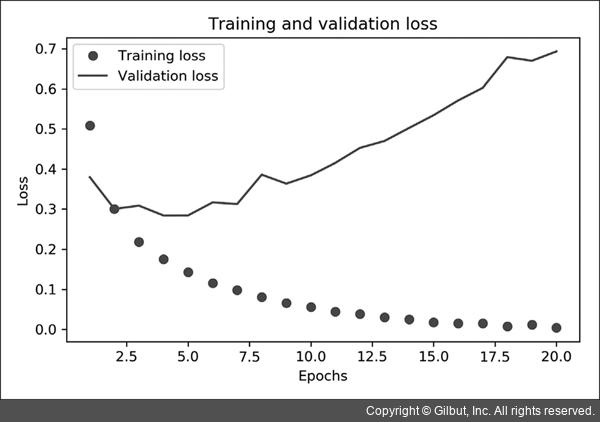 훈련과 검증 손실
훈련과 검증 손실
# code 3-10 훈련과 검증 정확도 그리기
plt.clf() # 그래프 초기화
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc, 'b', label = 'Validation acc')
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
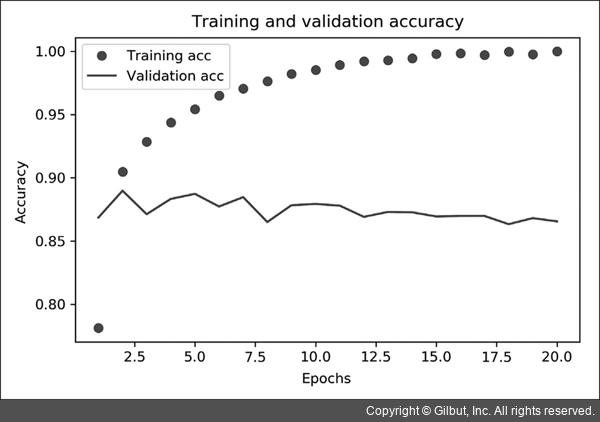
그래프에 나타나듯이 Training loss가 epochs마다 감소하고 Training acc는 epochs마다 증가합니다.
경사 하강법 최적화를 사용했을 때 반복마다 최소화되는 것이 손실이므로 기대했던 대로입니다.
Validation loss와 acc는 이와 같지 않습니다.
네 번째 epochs에서 그래프가 역전되는 것을 볼 수 있습니다. 이것이 바로 훈련 세트에서 잘 작동하는 모델이 처음 보는 데이터에서는 잘 작동하지 않을 수 있다고 앞서 말한 사례입니다.
즉 과대적합(overfitting)되었다고 할 수 있습니다.
두 번째 에포크 이후부터 훈련 데이터에 과도하게 최적화되어 훈련 데이터에 특화된 표현을 학습하므로 훈련 세트 이외의 데이터에는 일반화되지 못합니다.
overfitting을 방지하기 위해서 세 번째 에포크 이후에 훈련을 중지할 수 있습니다(early stopping).
너무 많은 Epoch는 overfitting을 일으킵니다. 하지만 너무 적은 Epoch은 underfitting을 일으킵니다.
이런 상황에서 적절한 Epoch를 정하는 방법으로 Early stopping을 사용합니다. Early stopping은 무조건 Epoch를 많이 돌린 후, 특정 시점에서 멈추는 것입니다.
그 특정 시점은 일반적으로 hold-out validation set에서의 성능이 더 이상 증가하지 않을 때 입니다.
# code 3-11 Early stopping
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activatoin='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
최종 결과입니다.
>>> results
[0.3231545869, 0.87348]
아주 단순한 방식으로 87%의 정확도를 달성했습니다.
3.4.5 훈련된 모델로 새로운 데이터에 대해 예측하기
이제 predict 메서드를 사용해서 어떤 리뷰가 긍정일 확률을 예측할 수 있습니다.
>>> model.predict(x_test)
array([[0.98006207]
[0.99758697]
[0.99975556]
... ,
[0.82167041]
[0.02885115]
[0.65371346]], dtype=float32)
이 모델은 어떤 샘플에 대해 확신을 가지고 있지만(0.99 이상 또는 0.01 ) 어떤 샘플에 대해서는 확신이 부족합니다(0.6).
3.4.6 추가 실험
- 1개 또는 3개의 hidden layer을 사용하고 검증과 테스트 정확도에 어떤 영향을 미치는지 확인하기
1개 일 때 검증 정확도: 0.8917999863624573
3개 일 때 검증 정확도: 0.8912000060081482
1개 일 때 테스트 정확도: 0.8828799724578857
3개 일 때 테스트 정확도: 0.8789600133895874 - 층의 hidden unit을 증가 및 감소시켜 수행하기(32개의 유닛, 64개의 유닛 등)
hidden unit 32개 일 때 손실: 0.2797657251358032
hidden unit 32개 일 때 정확도: 0.8885999917984009
hidden unit 64개 일 때 손실: 0.29155001044273376
hidden unit 64개 일 때 정확도: 0.8870999813079834 - binary_crossentropy 대신에 mse 손실 함수 사용해보기
loss: 0.09185122698545456
accuracy: 0.8863199949264526 - relu 대신에 tanh 활성화 함수 사용해보기
loss: 0.3065325915813446
accuracy: 0.8763200044631958
3.4.7 정리
- 원본 데이터를 신경망에 텐서로 주입하기 위해서 많은 전처리가 필요합니다.
- 이진 분류 문제(output class가 2개)에서 네트워크는 하나의 유닛과 sigmoid 활성화 함수를 가진 Dense 층으로 끝나야 합니다. 이 신경망의 출력은 확률을 나타내는 0 ~ 1 사이의 스칼라 값입니다.
- 이진 분류 문제에서 스칼라 시그모이드 출력에 대해 사용할 손실 함수는 binary_crossentropy입니다.
- rmsprop 옵티마이저는 문제에 상관없이 일반적으로 자주 쓰입니다.
- 훈련 데이터에 대해 성능이 향상됨에 따라 신경망은 overfitting되기 시작하고 이전에 본적 없는 데이터에서는 결과가 점점 나빠지게 됩니다. 항상 훈련 세트 이외의 데이터에서 성능을 모니터링해야 합니다.
Reference
- 케라스 창시자에게 배우는 딥러닝
- https://ssungkang.tistory.com/entry/%EB%94%A5%EB%9F%AC%EB%8B%9D05imdb-%EC%98%81%ED%99%94-%EB%A6%AC%EB%B7%B0-%EC%9D%B4%EC%A7%84-%EB%B6%84%EB%A5%98
- https://mongxmongx2.tistory.com/25
- https://ko.wikipedia.org/wiki/%EC%8B%9C%EA%B7%B8%EB%AA%A8%EC%9D%B4%EB%93%9C_%ED%95%A8%EC%88%98
- https://3months.tistory.com/424
