[DeepLearning] CH03. 신경망 시작하기(1)
in Deep Learning on Deeplearning
케라스 창시자에게 배우는 딥러닝을 기반으로 공부한 내용을 정리합니다.

3.1 신경망의 구조
신경망 훈련에 관련된 요소들
- 네트워크(또는 모델) 를 구성하는 층
- 입력 데이터 와 그에 상응하는 타깃
- 학습에 사용할 피드백 신호를 정의하는 손실함수
- 학습 진행 방식을 결정하는 옵티마이저
연속된 층으로 구성된 네트워크가 입력 데이터를 예측으로 매핑합니다. 손실 함수는 예측과 타깃을 비교하여 네트워크의 예측이 기댓값에 얼마나 잘 맞는지를 측정하는 손실 값을 만듭니다.(정답지 - 예측값 = 오차) 옵티마이저는 손실 값을 사용하여 네트워크 가중치를 업데이트합니다.
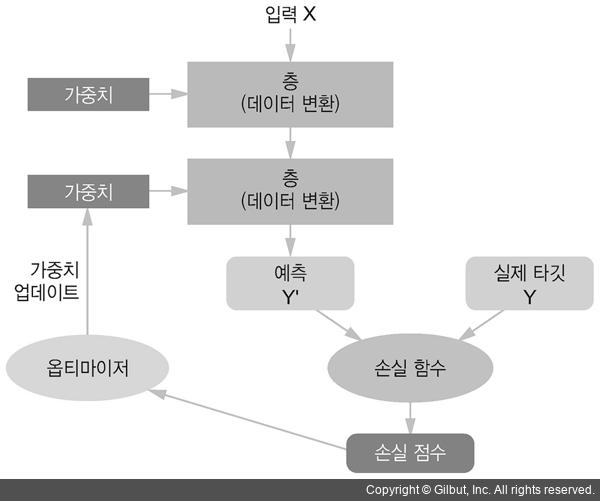
네드워크, 층, 손실함수, 옵티마이저 사이의 관계
3.1.1 층: 딥러닝의 구성 단위
층은 하나 이상의 텐서를 입력으로 받아 하나 이상의 텐서를 출력하는 데이터 처리 모듈입니다.
어떤 종류의 층은 상태가 없지만 대부분의 경우 가중치라는 층의 상태를 가집니다. 가중치는 확률적 경사 하강법에 의해 학습되는 하나 이상의 텐서이며 여기에 네트워크가 학습한 지식이 담겨 있습니다.
층마다 적절한 텐서 포맷과 데이터 처리 방식이 다릅니다.
예를 들어 (samples, features)크기의 2D 텐서가 저장된 간단한 벡터 데이터는 완전 연결 층(fully connected layer)이나 밀집 층(dense layer)이라고도 불리는 밀집 연결 층(densely connected layer)에 의해 처리되는 경우가 많습니다(케라스에서는 Dense 클래스입니다).
(samples, timesteps, features) 크기의 3D 텐서로 저장된 sequence data는 보통 LSTM 같은 순환 층(recurrent layer)에 의해 처리됩니다.
4D 텐서로 저장되어 있는 image data는 일반적으로 2D 합성곱 층(convolution layer)에 의해 처리됩니다(Conv2D 클래스)
케라스에서는 호환 가능한 층들을 엮어 데이터 변환 파이프라인(pipeline)을 구성함으로써 딥러닝 모델을 만듭니다.
층 호환성(layer compatibility)은 각 층이 특정 크기의 입력 텐서만 받고 특정 크기의 출력 텐서를 반환한다는 사실을 말합니다.
다음 예를 살펴보겠습니다.
from keras import layers
layer = layers.Dense(32, input_shape=(784,)) # 32개의 유닛으로 된 밀집 층
첫 번째 차원이 784인 2D 텐서만 입력으로 받는 층을 만들었습니다(배치 차원인 0번째 축은 지정하지 않기 때문에 어떤 배치 크기도 입력으로 받을 수 있습니다). 이 층은 첫 번째 차원 크기가 32로 변환된 텐서를 출력할 것입니다.
따라서 이 층에는 32차원의 벡터를 입력으로 받는 하위 층이 연결되어야 합니다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, input_shape=(784, )))
model.add(layers.Dense(10))
두 번째 층에는 input_shape 매개변수를 지정하지 않았습니다. 그 대신 앞선 층의 출력 크기를 입력 크기로 자동으로 채택합니다.
3.1.2 모델: 층의 네트워크
딥러닝 모델은 층으로 만든 비순환 유향 그래프(Directed Acyclic Graph, DAG)입니다. 하나의 입력을 하나의 출력으로 매핑하는 층을 순서대로 쌓는 것입니다.
네트워크 구조
- 가지(branch)가 2개인 네트워크
- 출력이 여러 개인 네트워크
- 인셉션(Inception) 블록
네트워크 구조는 가설 공간(hypothesis space)을 정의합니다.
네트워크 구조를 선택함으로써 가능성 있는 공간을 입력 데이터에서 출력 데이터로 매핑하는 일련의 특정 텐서 연산으로 제한하게 됩니다. 우리가 찾아야 할 것은 이런 텐서 연산에 포함된 가중치 텐서의 좋은 값입니다.
딱 맞는 네트워크 구조를 찾아내는 것은 현실적으로 쉽지 않습니다.
3.1.3 손실 함수와 옵티마이저: 학습 과정을 조절하는 열쇠
네트워크 구조를 정의하고 나면 두 가지를 더 선택해야 합니다.
- 손실 함수(loss function)(목적 함수 (objective function)): 훈련하는 동안 최소화될 값입니다. 주어진 문제에 대한 성공 지표가 됩니다.
- 옵티마이저(optimizer): 손실 함수를 기반으로 네트워크가 어떻게 업데이트될지 결정합니다. 특정 종류의 확률적 경사 하강법(SGD)을 구현합니다.
여러 개의 출력을 내는 신경망은 여러 개의 손실 함수를 가질 수 있습니다. 하지만 경사 하강법 과정은 하나의 스칼라 손실 값을 기준으로 합니다. 따라서 손실이 여러 개인 네트워크에서는 모든 손실이 (평균을 내서) 하나의 스칼라 양으로 합쳐집니다.
또한 문제에 맞는 올바른 목적 함수를 선택하는 것은 아주 중요합니다. 그 이유는 바로 네트워크가 손실을 최소화하기 위해 편법을 사용할 수 있기 때문입니다. 목적 함수가 주어진 문제의 성공과 전혀 관련이 없다면 원하지 않는 일을 수행하는 모델이 만들어질 것입니다.
“모든 인류의 평균 행복 지수를 최대화하기” 같은 잘못된 목적 함수에서 SGD로 훈련된 멍청하지만 전지전능한 AI가 있다고 가정하겠습니다. 문제 해결을 위해 이 AI가 몇 사람을 남기고 모든 인류를 죽여서 남은 사람들의 행복에 초점을 맞출지도 모릅니다. 왜냐하면 평균적인 행복은 얼마나 많은 사람이 남겨져 있는지와 상관없기 때문입니다.
이는 분명 의도한 바와 다를 것입니다.
우리가 만든 모든 신경망은 단지 손실 함수를 최소화하기만 한다는 것을 기억해야 합니다. 목적 함수를 현명하게 선택하지 않으면 원하지 않는 부수 효과가 발생할 것입니다.
분류, 회귀와 시퀀스 예측 같은 문제에서의 손실 함수 선택
2개의 클래스가 있는 분류 문제에는 이진 크로스엔트로피(binary crossentropy), 여러 개의 클래스가 있는 분류 문제에는 범주형 크로스엔트로피(categorical crossentropy), 회귀 문제에는 평균 제곱 오차, 시퀀스 학습 문제에는 CTC(Connection Temporal Classification) 등을 사용합니다.
3.2 케라스 소개
케라스 특징
- 동일한 코드로 CPU와 GPU에서 실행할 수 있습니다.
- 사용하기 쉬운 API를 가지고 있어 딥러닝 모델의 프로토타입을 빠르게 만들 수 있습니다.
- (컴퓨터 비전을 위한) 합성곱 신경망, (시퀀스 처리를 위한) 순환 신경망을 지원하며 이 둘을 자유롭게 조합하여 사용할 수 있습니다.
- 다중 입력이나 다중 출력 모델, 층의 공유, 모델 공유 등 어떤 네트워크 구조도 만들 수 있습니다.
3.2.1 케라스, 텐서플로, 씨아노, CNTK
케라스는 딥러닝 모델을 만들기 위한 고수준의 구성 요소를 제공하는 모델 수준의 라이브러리입니다. 텐서 조작이나 미분 같은 저수준의 연산을 다루지 않습니다.
대신에 케라스의 백엔드 엔진(backend engine)에서 제공하는 최적화되고 특화된 텐서 라이브러리를 사용합니다. 케라스는 하나의 텐서 라이브러리에 국한하여 구현되어 있지 않고 모듈 구조로 구성되어 있습니다.
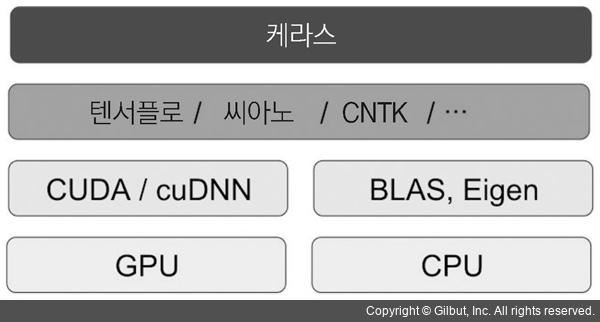
DeepLearning Software & Hardware stack
3.2.2 케라스를 사용한 개발: 빠르게 둘러보기
전형적인 케라스 작업 흐름은 아래와 비슷합니다.
- 입력 텐서와 타깃 텐서로 이루어진 훈련 데이터를 정의합니다.
- 입력과 타깃을 매핑하는 층으로 이루어진 네트워크(또는 모델)를 정의합니다.
- 손실 함수, 옵티마이저, 모니터링하기 위한 측정 지표를 선택하여 학습 과정을 설정합니다.
- 훈련 데이터에 대해 모델의 fit() 메서드를 반복적으로 호출합니다.
모델을 정의하는 방법은 두 가지인데, Sequential() 클래스(가장 자주 사용하는 구조인 층을 순서대로 쌓아 올린 네트워크입니다) 또는 함수형 API(완전히 임의의 구조를 만들 수 있는 비순환 유향 그래프를 만듭니다)를 사용합니다.
Sequential() 클래스를 사용하여 정의한 2개의 층으로 된 모델을 살펴보겠습니다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(784,)))
model.add(layers.Dense(10, activation = 'softmax'))
# 같은 모델을 함수형 API를 사용하여 만들어 보겠습니다.
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32, activation = 'relu')(input_tensor)
output_tensor = layers.Dense(10, activation = 'softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
함수형 API를 사용하면 모델이 처리할 데이터 텐서를 만들고 마치 함수처럼 이 텐서에 층을 적용합니다.
모델 구조가 정의된 후에는 Sequential 모델을 사용했는지 함수형 API를 사용했는지 상관없습니다.
이후 컴파일 단계에서 학습 과정이 설정됩니다. 모델이 사용할 옵티마이저와 손실 함수, 훈련하는 동안 모니터링하기 위해 필요한 측정 지표를 지정합니다.
from keras import optimizers
model.compile(optimizer = optimizers.RMSprop(lr=0.001),
loss = 'mse',
metrics=['accuracy'])
마지막으로 입력 데이터의 넘파이 배열을 (그리고 이에 상응하는 타깃 데이터를) 모델의 fit() 메서드에 전달함으로써 학습 과정이 이루어집니다.
model.fit(input_tensor, target_tensor, batch_size = 128, epochs = 10)
Reference
- 케라스 창시자에게 배우는 딥러닝
