[DeepLearning] CH02. 신경망의 수학적 구성 요소(2)
in Deep Learning on Deeplearning
케라스 창시자에게 배우는 딥러닝을 기반으로 공부한 내용을 정리합니다.

2.2 신경망을 위한 데이터 표현
텐서는 데이터를 위한 컨테이너(container)입니다. 텐서는 임의의 차원 개수를 가지는 행렬의 일반화된 모습입니다.(차원(dimension)을 종종 축(axis)이라고 부릅니다)
2.2.1 스칼라(0D 텐서)
하나의 숫자만 담고 있는 텐서를 스칼라(scalar)(또는 스칼라 텐서, 0차원 텐서, 0D 텐서)라고 부릅니다. ndim 속성을 사용하면 넘파이 배열의 축 개수를 확인할 수 있습니다. 스칼라 텐서의 축 개수는 0입니다.(ndim == 0). 텐서의 축 개수를 랭크(rank)라고 부릅니다.
import numpy as np
x = np.array(12)
>>> x
array(12)
>>> x.ndim
0
2.2.2 벡터(1D 텐서)
숫자의 배열을 벡터(vector) 또는 1D 텐서라고 부릅니다. 1D 텐서는 딱 하나의 축을 가집니다.
x = np.arrary([12, 3, 6, 14, 7])
>>> x
array([12, 3, 6, 14, 7])
>>> x.ndim
1
이 벡터는 5개의 원소를 가지고 있으므로 5차원 벡터라고 부릅니다.
5D 벡터는 하나의 축을 따라 5개의 차원을 가진 것이고 5D 텐서는 5개의 축을 가진 것이므로 둘을 혼동해서는 안되겠습니다.
2.2.3 행렬(2D 텐서)
벡터의 배열이 행렬(maxtrix) 또는 2D 텐서입니다. 행렬에는 2개의 축이 있습니다.(보통 행(row)과 열(column)이라고 부릅니다)
x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
>>> x.ndim
2
첫 번째 축에 놓여 있는 원소를 행이라 부르고, 두 번째 축에 놓여 있는 원소를 열이라 부릅니다. 앞의 예에서 x의 첫 번째 행은 [5, 78, 2, 34, 0]이고, 첫 번째 열은 [5, 6, 7]입니다.
스칼라, 벡터 그리고 행렬을 표현하면 아래와 같습니다. 
2.2.4 3D 텐서와 고차원 텐서
x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
>>> x.ndim
3
3D 텐서들을 하나의 배열로 합치면 4D 텐서를 만드는 식으로 이어집니다.
2.2.5 핵심 속성
텐서는 3개의 핵심 속성으로 정의됩니다.
- 축의 개수(랭크): 예를 들어 3D 텐서에는 3개의 축이 있고, 행렬에는 2개의 축이 있습니다. ndim 속성으로 확인할 수 있습니다.
- 크기(shape): 텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 파이썬의 튜플(tuple)입니다. 예를 들어 앞에 나온 행렬의 크기는 (3,5)이고 3D 텐서의 크기는 (3, 3, 5)입니다. 벡터의 크기는 (5,)처럼 1개의 원소로 이루어진 튜플입니다. 배열 스칼라는 ()처럼 크기가 없습니다.
- 데이터 타입(넘파이에서는 dtype에 저장): 텐서의 타입은 float32, uint8, float64 등이 있습니다.
dtype 속성으로 데이터 타입을 확인할 수 있습니다.
>>> print(train_images.dtype)
uint8 # 정수형
# code 2-6 다섯 번째 이미지 출력하기
digit = train_images[4]
import matplotlib.pyplot as plt
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
데이터 셋에 있는 다섯 번째 샘플 
2.2.6 넘파이로 텐서 조작하기
배열에 있는 특정 원소들을 선택하는 것을 슬라이싱(slicing)이라고 합니다.
다음 예는 11번째에서 101번째까지(101번째는 포함하지 않고) 숫자를 선택하여 (90, 28, 28) 크기의 배열을 만듭니다.
>>> my_slice = train_images[10:100]
>>> print(my_slice.shape)
(90, 28, 28)
이미지의 오른쪽 아래 14 * 14픽셀을 선택할 수도 있습니다.
my_slice = train_images[:, 14:, 14:]
2.2.7 배치 데이터
일반적으로 딥러닝에서 사용하는 모든 데이터 텐서의 첫 번째 축(인덱스가 0부터 시작하므로 0번째 축은) 샘플 축(sample axis)입니다.(이따금 샘플 차원(sample dimension))이라고도 부릅니다)
딥러닝 모델은 한 번에 전체 데이터셋을 처리하지 않습니다. 대신 데이터를 작은 배치(batch)로 나눕니다.
batch = train_images[:128] # 크기가 128인 배치
batch = train_images[128:256] # 그 다음 배치
batch = train_images[128 * n:128 * (n + 1)] # n번째 배치
이런 배치 데이터를 다룰 때는 첫 번째 축(0번 축)을 배치 축(batch axis) 또는 배치 차원(batch dimension)이라고 부릅니다.
2.2.8 텐서의 실제 사례
- 벡터 데이터: (samples, features) 크기의 2D 텐서
- 시계열 데이터 또는 시퀀스(sequence)데이터: (samples, timesteps, features)크기의 3D텐서
- 이미지: (samples, height, width, channels) 또는 (samples, channels, height, width) 크기의 4D 텐서
- 동영상: (samples, frames, height, width, channels) 또는 (samples, frames, channels, height, width) 크기의 5D 텐서
2.2.9 벡터 데이터
하나의 데이터 포인트가 벡터로 인코딩될 수 있으므로 배치 데이터는 2D 텐서로 인코딩될 것입니다.(즉 벡터의 배열입니다) 여기서 첫 번째 축은 샘플 축이고, 두 번째 축은 특성 축입니다.
2개의 예를 살펴보겠습니다.
- 사람의 나이, 우편 번호, 소득으로 구성된 인구 통계 데이터. 각 사람은 3개의 값을 가진 벡터로 구성되고 10만명이 포함된 전체 데이터셋은 (100000, 3)크기의 텐서에 저장될 수 있습니다.
- (공통 단어 2만개로 만든 사전에서) 각 단어가 등장한 횟수로 표현된 텍스트 문서 데이터셋. 각 문서는 2만 개의 원소(사전에 있는 단어마다 하나의 원소에 대응합니다)를 가진 벡터로 인코딩될 수 있습니다. 500개의 문서로 이루어진 전체 데이터셋(500, 20000)크기의 텐서로 저장됩니다.
2.2.10 시계열 데이터 또는 시퀀스 데이터
데이터에서 시간이 (또는 연속된 순서가) 중요할 때는 시간 축을 포함하여 3D 텐서로 저장됩니다.
관례적으로 시간 축은 항상 두 번째 축(인덱스가 1인 축)입니다.
몇 가지 예를 들어 보겠습니다.
- 주식 가격 데이터셋: 1분마다 현재 주식 가격, 지난 1분 동안에 최고 가격과 최소 가격을 저장합니다. 1분마다 데이터는 3D 벡터로 인코딩되고 하루 동안의 거래는 (390, 3)크기의 2D 텐서로 인코딩됩니다.(하루의 거래 시간은 390분) 250일치의 데이터는 (250, 390, 3) 크기의 3D 텐서로 저장될 수 있습니다.
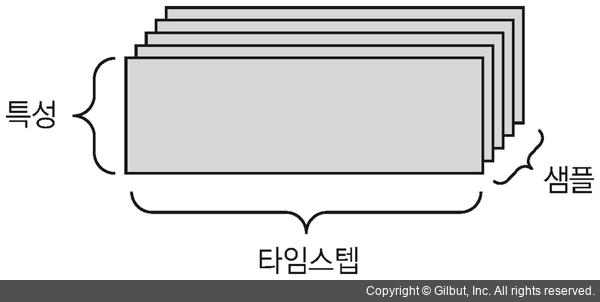 3D 시계열 데이터 텐서
3D 시계열 데이터 텐서
2.2.11 이미지 데이터
이미지는 높이, 너비, 컬러 채널의 3차원으로 이루어집니다.
흑백 이미지는 하나의 컬러 채널만을 가지고 있어 2D 텐서로 저장될 수 있지만 관례상 이미지 텐서는 항상 3D로 저장됩니다. 흑백 이미지의 경우 컬러 채널의 차원 크기는 1입니다.
256 * 256 크기의 흑백 이미지에 대한 128개의 배치는 (128, 256, 256, 1) 크기의 텐서에 저장될 수 있습니다.
컬러 이미지에 대한 128개의 배치는 (128, 256, 256, 3)크기의 텐서에 저장될 수 있습니다.
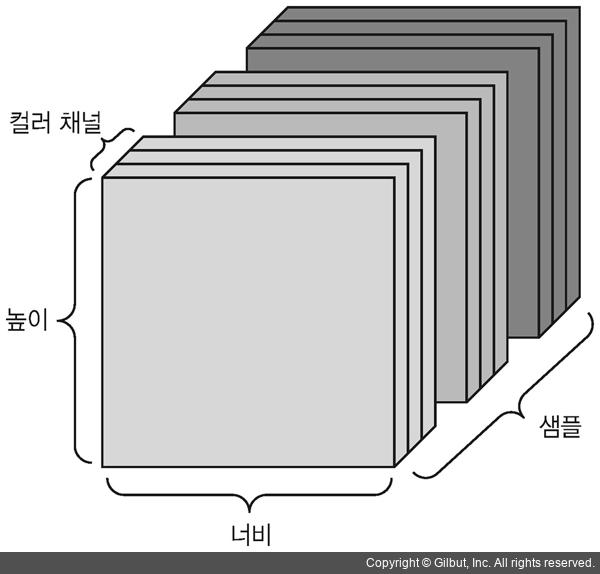 4D 이미지 데이터 텐서(채널 우선 표기)
4D 이미지 데이터 텐서(채널 우선 표기)
2.2.12 비디오 데이터
하나의 비디오는 프레임의 연속이고 각 프레임은 하나의 컬러 이미지입니다.
프레임이 (height, width, color_depth)의 3D 텐서로 저장될 수 있기 때문에 프레임의 연속은 (frames, height, width, color_depth)의 4D 텐서로 저장될 수 있습니다.
여러 비디오의 배치는 (samples, frames, height, width, color_depth)의 5D 텐서로 저장될 수 있습니다.
예를 들어 60초 짜리의 144 * 256 유튜브 비디오 클립을 초당 4프레임으로 샘플링하면 240프레임이 됩니다.(60초 * 4프레임) 이런 비디오 클립을 4개 가진 배치는 (4, 240, 144, 256, 3)크기의 텐서에 저장될 수 있습니다.
이번 시간에는 신경망을 위한 각 데이터들의 표현에 대해 살펴보았습니다. 다음 시간에는 텐서 연산에 대해 알아보겠습니다.
Reference
- 케라스 창시자에게 배우는 딥러닝
