[Hadoop] Hadoop CH 6 정렬 part2:보조 정렬 실행 및 부분 정렬
in Data Engineering on Hadoop
시작하세요 하둡 프로그래밍을 기반으로 공부한 내용을 정리합니다. - CH6 part2:보조 정렬 실행 및 부분 정렬

보조 정렬 실행
- 추후 보강
부분 정렬(Partial Sort)
부분 정렬(Partial Sort)은 매퍼의 출력 데이터를 변경해 정렬하여 원하는 키의 데이터를 검색하는 방법입니다.
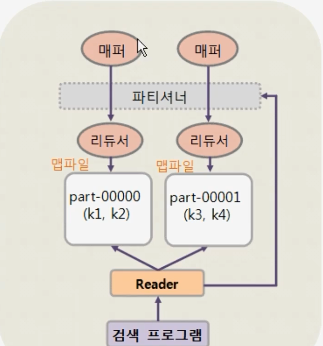
Mapper의 출력 데이터를 맵파일(Mapfile) 형태로 변경
Partitioner는 Mapper의 출력 데이터가 어떤 Reduce task로 전달될지 결정
Partitioning된 데이터는 키에 따라 정렬
특정 키에 대한 데이터를 검색할 때, 해당 키에 대한 데이터가 저장되어 있는 맵파일(Mapfile)에 접근해서 데이터를 조회
항공 지연 데이터를 항공 운항 거리 순서대로 정렬하는 부분 정렬 프로그램은 다음과 같은 과정으로 구현합니다.
입력 데이터를 시퀀스 파일로 생성합니다.
시퀀스 파일을 맵파일(Mapfile)로 변경합니다.
맵파일(Mapfile)에서 데이터를 검색합니다.
시퀀스 파일 생성
항공 운항 지연 데이터를 시퀀스 파일로 출력합니다. 입력 {K, V} = {오프셋(LongWritable), 항공 운항 데이터(Text)}, 출력 = {운항거리(IntWritable), 항공 운항 데이터(Text)}
항공 운항 거리를 출력 데이터의 키로 설정합니다.
SequenceFileCreator.java ... AirlinePerformanceParser parser = new AirlinePerformanceParser(value); if (parser.isDistanceAvailable()) { outputKey.set(parser.getDistance()); output.collect(outputKey, value); } ...출력 데이터 포맷을 시퀀스 파일로 설정합니다.
SequenceFileCreator.java ... conf.setOutputFormat(SequenceFileOutputFormat.class); conf.setOutputKeyClass(IntWritable.class); conf.setOutputValueClass(Text.class); ...시퀀스 파일의 압축 포맷은 SequenceFileOutputFormat내의 메서드를 이용합니다.
SequenceFileCreator.java ... SequenceFileOutputFormat.setCompressOutput(conf, true); SequenceFileOutputFormat.setOutputCompressorClass(conf, GzipCodec.class); SequenceFileOutputFormat.setOutputCompressionType(conf, CompressionType.BLOCK); ...전체 코드
접기/펼치기
SequenceFileCreator.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import wikibooks.hadoop.common.AirlinePerformanceParser;
import java.io.IOException;
public class SequenceFileCreator extends Configured implements Tool {
static class DistanceMapper extends MapReduceBase implements
Mapper<LongWritable, Text, IntWritable, Text> {
private IntWritable outputKey = new IntWritable();
public void map(LongWritable key, Text value,
OutputCollector<IntWritable, Text> output, Reporter reporter)
throws IOException {
try {
AirlinePerformanceParser parser = new AirlinePerformanceParser(value);
if (parser.isDistanceAvailable()) {
outputKey.set(parser.getDistance());
output.collect(outputKey, value);
}
} catch (ArrayIndexOutOfBoundsException ae) {
outputKey.set(0);
output.collect(outputKey, value);
ae.printStackTrace();
} catch (Exception e) {
outputKey.set(0);
output.collect(outputKey, value);
e.printStackTrace();
}
}
}
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(SequenceFileCreator.class);
conf.setJobName("SequenceFileCreator");
conf.setMapperClass(DistanceMapper.class);
conf.setNumReduceTasks(0);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setOutputFormat(SequenceFileOutputFormat.class);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
SequenceFileOutputFormat.setCompressOutput(conf, true);
SequenceFileOutputFormat.setOutputCompressorClass(conf, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(conf, CompressionType.BLOCK);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new SequenceFileCreator(), args);
System.out.println("MR-Job Result:" + res);
}
}
맵 파일 생성
맵파일은 index 파일과 데이터 내용이 저장되어있는 data 파일로 구성됩니다.
이전에 만든 시퀀스 파일을 변환해 맵파일로 생성할 수 있습니다.
입력 데이터 형식을 시퀀스 파일로, 출력 형식은 맵파일로 설정하고 출력 키값을 전입월로 설정합니다.
MapFileCreator.java ... conf.setInputFormat(SequenceFileInputFormat.class); conf.setOutputFormat(MapFileOutputFormat.class); conf.setOutputKeyClass(IntWritable.class); ...전체 코드
접기/펼치기
MapFileCreator.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MapFileCreator extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MapFileCreator(), args);
System.out.println("MR-Job Result:" + res);
}
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(MapFileCreator.class);
conf.setJobName("MapFileCreator");
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setInputFormat(SequenceFileInputFormat.class);
conf.setOutputFormat(MapFileOutputFormat.class);
conf.setOutputKeyClass(IntWritable.class);
SequenceFileOutputFormat.setCompressOutput(conf, true);
SequenceFileOutputFormat.setOutputCompressorClass(conf, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(conf, CompressionType.BLOCK);
JobClient.runJob(conf);
return 0;
}
}
검색 프로그램 구현
맵파일에서 원하는 키에 해당하는 값을 검색하는 방법에 대해 구현합니다.
원하는 데이터만 검색하면 되므로 맵리듀스로 구현할 필요 없이, 검색키인 파티션 번호로 맵파일에 접근해 데이터를 검색합니다.
맵파일을 읽기 위해 파일 시스템 객체를 생성합니다.
SearchValueList.java ... Path path = new Path(args[0]); FileSystem fs = path.getFileSystem(getConf()); ...맵파일에 저장된 데이터를 읽습니다.
SearchValueList.java ... Reader[] readers = MapFileOutputFormat.getReaders(fs, path, getConf()); ...파티션 정보를 얻기 위해 해시 파티셔너를 생성하고 파티션 번호를 반환받습니다.
SearchValueList.java ... Partitioner<IntWritable, Text> partitioner = new HashPartitioner<IntWritable, Text>(); Reader reader = readers[partitioner.getPartition(key, value, readers.length)]; ...반환받은 파티션 번호를 이용해 특정 키에 해당하는 값을 검색합니다.
SearchValueList.java ... Writable entry = reader.get(key, value); ...
이를 실행하면 오류가 발생합니다.
MapFileOutputFormat이 이전 맵리듀스 잡에서 생성한 로그 파일 폴더를 체크해 오류가 발생합니다.
따라서 이를 모두 삭제한 후 다시 실행하면 정상적으로 데이터가 출력됩니다.
- 전체 코드
접기/펼치기
SearchValueList.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapFile.Reader;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.MapFileOutputFormat;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.lib.HashPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SearchValueList extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new SearchValueList(), args);
System.out.println("MR-Job Result:" + res);
}
public int run(String[] args) throws Exception {
Path path = new Path(args[0]);
FileSystem fs = path.getFileSystem(getConf());
Reader[] readers = MapFileOutputFormat.getReaders(fs, path, getConf());
IntWritable key = new IntWritable();
key.set(Integer.parseInt(args[1]));
Text value = new Text();
Partitioner<IntWritable, Text> partitioner = new HashPartitioner<IntWritable, Text>();
Reader reader = readers[partitioner.getPartition(key, value, readers.length)];
Writable entry = reader.get(key, value);
if (entry == null) {
System.out.println("The requested key was not found.");
}
IntWritable nextKey = new IntWritable();
do {
System.out.println(value.toString());
} while (reader.next(nextKey, value) && key.equals(nextKey));
return 0;
}
}
특정 키에 해당하는 데이터만 검색해서 사용하는 경우, 부분 정렬을 활용하면 도움이 됩니다.
전체 정렬(Total Sort)
많은 양의 데이터를 전체 정렬할 경우 리듀스 태스크가 실행되지 않은 데이터 노드는 가동되지 않고, 리듀스 테스크가 실행되는 데이터 노드에만 부하가 집중되는 문제가 발생합니다.
분산 처리의 장점을 유지하고 전체 정렬하려면,
입력 데이터를 샘플링해서 데이터의 분포도를 조사합니다.
데이터의 분포도에 맞게 파티션 정보를 미리 생성합니다.
출력 데이터를 생성하고 병합합니다.
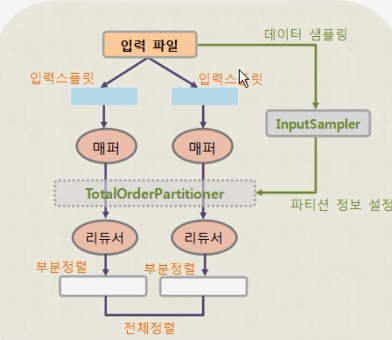
입력 데이터 샘플링
10개의 입력 스플릿에서 0.1%의 확률로 1000건의 데이터를 샘플링하고, 파티션 파일에 샘플러가 제공하는 키의 정보를 설정합니다.
SequenceFileTotalSort.java ... InputSampler.Sampler<IntWritable, Text> sampler = new InputSampler.RandomSampler<IntWritable, Text>(0.1, 1000, 10); InputSampler.writePartitionFile(conf, sampler); ...
파티션 정보 생성
데이터의 분포에 맞게 파티션의 정보를 생성합니다.
SequenceFileTotalSort.java ... URI partitionUri = new URI(partitionFile.toString() + "#_partitions"); DistributedCache.addCacheFile(partitionUri, conf); DistributedCache.createSymlink(conf); ...전체 코드
접기/펼치기
SequenceFileTotalSort.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.InputSampler;
import org.apache.hadoop.mapred.lib.TotalOrderPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class SequenceFileTotalSort extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new SequenceFileTotalSort(), args);
System.out.println("MR-Job Result:" + res);
}
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(getConf(), SequenceFileTotalSort.class);
conf.setJobName("SequenceFileTotalSort");
conf.setInputFormat(SequenceFileInputFormat.class);
conf.setOutputFormat(SequenceFileOutputFormat.class);
conf.setOutputKeyClass(IntWritable.class);
conf.setPartitionerClass(TotalOrderPartitioner.class);
SequenceFileOutputFormat.setCompressOutput(conf, true);
SequenceFileOutputFormat.setOutputCompressorClass(conf, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(conf, CompressionType.BLOCK);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
Path inputDir = FileInputFormat.getInputPaths(conf)[0];
inputDir = inputDir.makeQualified(inputDir.getFileSystem(conf));
Path partitionFile = new Path(inputDir, "_partitions");
TotalOrderPartitioner.setPartitionFile(conf, partitionFile);
InputSampler.Sampler<IntWritable, Text> sampler = new InputSampler.RandomSampler<IntWritable, Text>(
0.1, 1000, 10);
InputSampler.writePartitionFile(conf, sampler);
URI partitionUri = new URI(partitionFile.toString() + "#_partitions");
DistributedCache.addCacheFile(partitionUri, conf);
DistributedCache.createSymlink(conf);
JobClient.runJob(conf);
return 0;
}
}
정렬 마무리
분산 환경의 장점을 살리면서 정렬하는 방법에는 세 가지가 있고 가갂의 특징은,
보조 정렬 => 키 값 그룹핑, 그룹핑된 레코드에 순서 부여
부분 정렬 => 특정 키에 대한 데이터 검색
전체 정렬 => 데이터 전체 정렬
입니다.
하둡 사용자가 상황에 따라 적절히 정렬 알고리즘을 선택해서 구현할 수 있습니다.
Reference
- 시작하세요 하둡 프로그래밍
- 어초 어초님 tistory 블로그
- 단다의 데이터과학 이야기
