[Hadoop] Hadoop CH 4 맵리듀스 시작하기
in Data Engineering on Hadoop
시작하세요 하둡 프로그래밍을 기반으로 공부한 내용을 정리합니다.
맵리듀스 시작하기
맵리듀스(Mapreduce)란?
- 맵리듀스 프로그래밍 모델은 맵(Map)과 리듀스(Reduce) 두 가지 단계로 구분되어 데이터를 처리합니다.
- 맵 : 입력 파일을 한 줄씩 읽어서 데이터를 변형
- 리듀스 : 맵의 결과 데이터를 집계
- 맵리듀스 프로그래밍 모델의 처리 과정입니다.
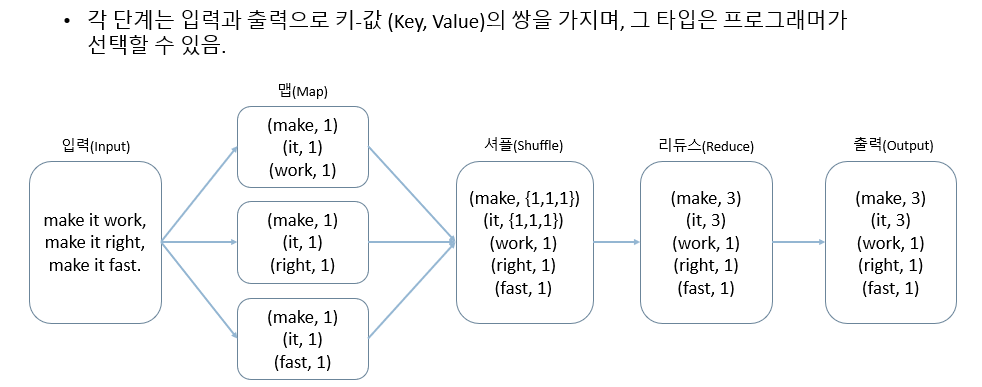
맵은 한 줄에 있는 단어 개수를 계산해 한 줄씩 출력합니다.
- 예를 들어, make it work는 make, it, work 세 가지 단어로 구성돼 있으므로 각각의 단어의 개수인 1이 value 값으로 정해집니다.
셔플은 맵에서 리듀스로 데이터를 전달하는 과정입니다.
- 메모리에 저장되어 있는 맵 함수의 출력 데이터를 파티셔닝과 정렬과정을 거쳐 리듀스의 입력 데이터로 전달합니다.
- (make, 1)이 전체 과정에서 3회 등장하므로, (make, {1,1,1})로 표현할 수 있습니다.
리듀스는 단어 목록들을 반복적으로 수행하고 합을 계산합니다.
- 리듀스는 맵의 출력 데이터를 집계합니다. 그래서 맵의 출력 데이터에는 단어의 개수인 1이 있었지만, 리듀스의 출력 파일에는 make, it은 3, work, right, fast는 1이 있습니다.
맵리듀스 아키택처
- 맵리듀스 시스템은 클라이언트, 잡 트래커, 태스크트래커로 구성됩니다.
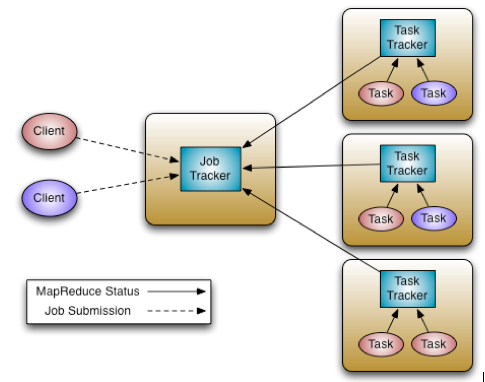
Client
- Client는 사용자가 실행한 맵리듀스 프로그램과 하둡에서 제공하는 맵리듀스 API를 의미합니다.
Job Tracker
- Client가 하둡으로 실행을 요청하는 맵리듀스 프로그램은 잡(job)이라는 하나의 작업 단위로 관리됩니다.
- Job Tracker는 하둡 클러스터에 등록된 전체 Job의 스케줄링을 관리하고 모니터링합니다.
- 전체 하둡 클러스터에서 하나의 Job Tracker가 실행되며, 보통 하둡의 네임노드 서버에서 실행됩니다.(반드시 네임노드에서 실행할 필요는 없음.)
- Job Tracker는 잡을 처리하기 위해 몇 개의 맵과 리듀스를 실행할지 계산합니다.
- 계산된 맵과 리듀스를 어떤 Task Tracker에서 실행할지 결정하고 해당 Task Tracker에 Job을 할당합니다.
- Job Tracker와 Task Tracker는 하트비트라는 메서드로 네트워크 통신을 하면서, Task Tracker의 상태와 작업 정보를 주고 받습니다.(장애 발생 시 다른 Task Tracker를 찾아 재실행.)
Task Tracker
- 사용자가 설정한 맵리듀스 프로그램을 실행하며, 하둡의 데이터노드에서 실행되는 데몬입니다.
- Job Tracker가 할당한 맵과 리듀스 개수 만큼 맵 태스크(Map task)와 리듀스 태스크(Reduce task)를 생성합니다.
- 태스크가 생성되면 여러개의 JVM을 실행해 데이터를 동시에 분석합니다. => 병렬처리 특성
데이터 플로우
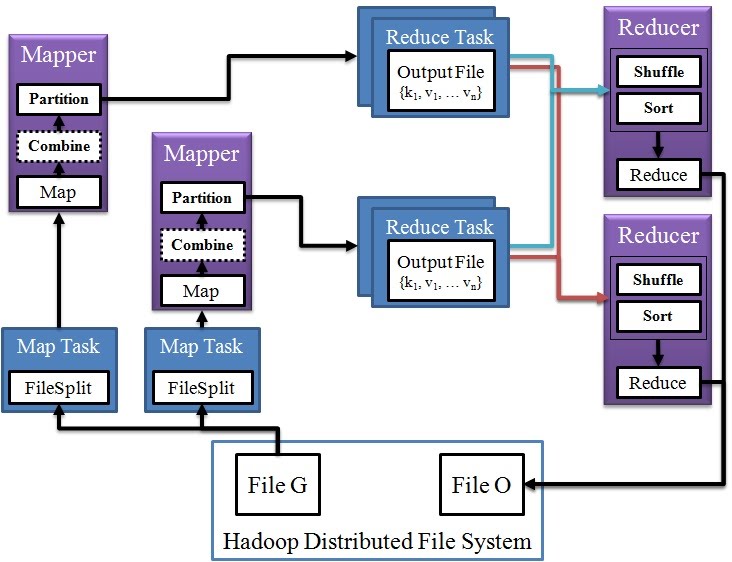
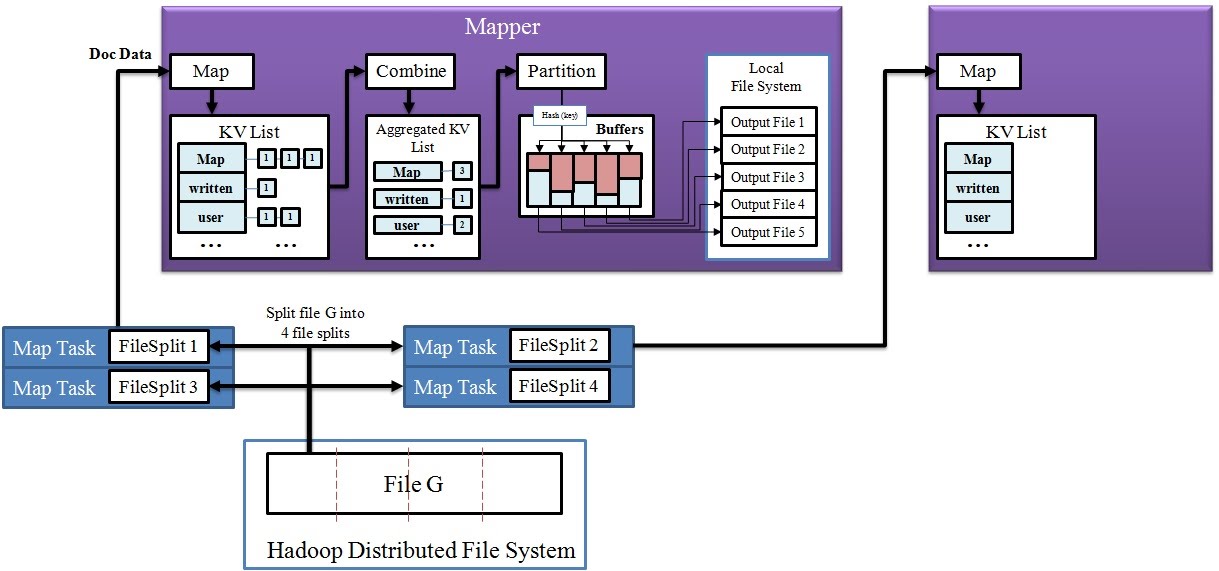
1. Mapper
Split
- HDFS에 저장되어 있는 입력 파일을 분할하여 InputSplit을 생성합니다.
- 이때, HDFS에 저장된 블록이 실제로 다시 분리되는 것이 아니라, 가상으로 블록을 분리합니다.
- InputSplit 하나 당 맵 태스크 하나씩 생성합니다.
- 만약 입력 파일이 100MB이고, HDFS의 기본 블록 크기가 64MB라면, 두 개의 입력 스플릿이 생성됩니다.
Map
- InputSplit을 읽어와서 Key-Value 쌍을 생성합니다.
Combine & Partition
- 디스크에 쓰기 전에 Key-Value 쌍 list에 대한 전처리를 수행. => Combine
- 키를 기준으로 디스크에 분할 저장(해시 파티셔닝). => Partition
- HDFS가 아닌, 맵퍼의 Local file system에 저장되고 분할된 파일은 다른 리듀스 task에 저장됩니다.
Map 과정
2. Reducer
Shuffle
- 여러 Mapper에 있는 결과 파일을 각 Reducer에 할당
Sort
- 병합 정렬(Merge sort)를 이용하여 Mapper 결과 파일을 정렬/병합 합니다.
- Key로 정렬된 하나의 커다란 파일이 생성됩니다.
Reduce
- Sort 단계에서 생성된 파일을 처음부터 순차적으로 읽으면서 reduce 함수를 수행합니다.
- <key, (list of values)> 쌍에 대해 <key, sum of values>로 바꿉니다.
Reduce 과정 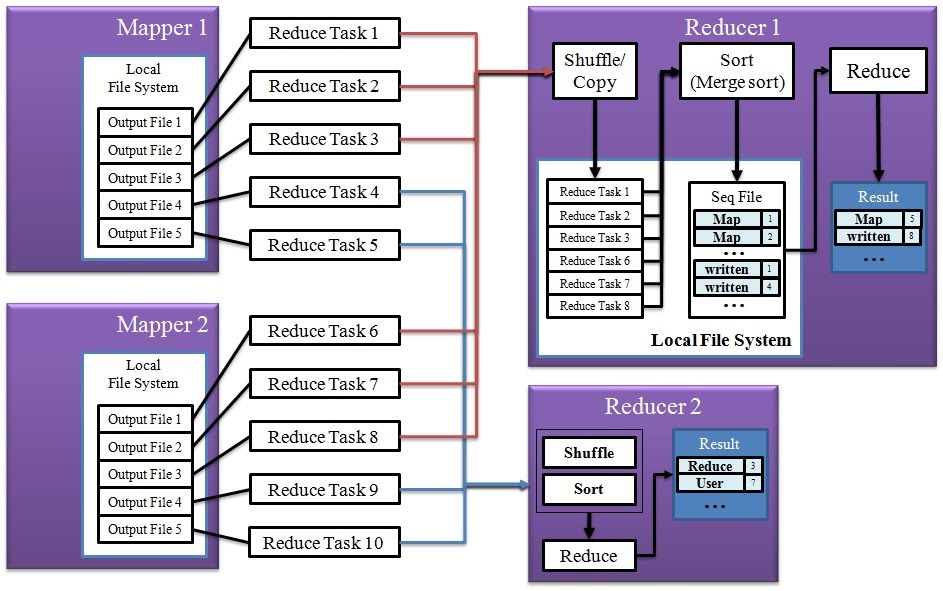
맵리듀스 프로그래밍
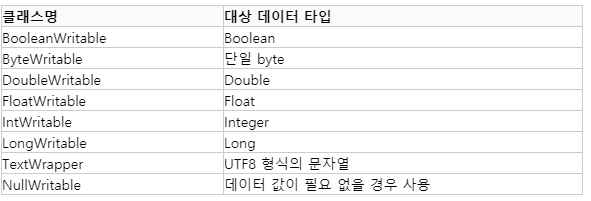
데이터 타입
- 맵리듀스는 네트워크 통신을 위한 최적화된 객체로 WirtableComparable 인터페이스를 제공합니다.
- 기본적으로 제공하는 타입은 아래와 같습니다.
Mapper
코드
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // Mapper<입력키, 입력값, 출력키, 출력값>
// ↓ 내포클래스 = Inner Class
public class Context
extends MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
public Context(Configuration conf, TaskAttemptID taskid,
RecordReader<KEYIN,VALUEIN> reader,
RecordWriter<KEYOUT,VALUEOUT> writer,
OutputCommitter committer,
StatusReporter reporter,
InputSplit split) throws IOException, InterruptedException {
super(conf, taskid, reader, writer, committer, reporter, split);
}
}
protected void setup(Context context) throws IOException, InterruptedException {
// NOTHING
}
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
protected void cleanup(Context context) throws IOException, InterruptedException {
// NOTHING
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try{
while(context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
}finally{
cleanup(context);
}
}
}
- 맵 함수는 추상 map( ) 메소드를 정의하는 Mapper 클래스로 구현됩니다.
- Mapper 클래스는 제네릭(generic) 타입으로, 네 개의 정규 타입 매개변수(입력 키, 입력 값, 출력 키, 출력 값)을 가집니다.
- MapContext를 상속받은 Context객체를 선언합니다.
- Context 객체를 이용해 job에 대한 정보를 얻어오고, 입력스플릿을 레코드단위로 읽을 수 있습니다. => RecordReader<KEYIN,VALUEIN> reader
- 맵리듀스 프로그램을 개발할 때 대부분 map() 메소드를 재정의합니다.
Partitioner
코드
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
- 맵테스크의 출력키, 출력값, 전체 리듀스테스크 개수를 파라미터로 받아서 해쉬함수를 사용해 파티션을 계산합니다. => getPartition
Reducer
코드
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // Reducer<입력키유형, 입력값유형, 출력키유형, 출력값유형>
// ↓ 내포클래스 = Inner Class
public class Context extends ReduceContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
public Context(Configuration conf, TaskAttemptID taskid,
RawKeyValueIterator input,
Counter inputKeyCounter,
Counter inputValueCounter,
RecordWriter<KEYOUT,VALUEOUT> output,
OutputCommitter committer,
StatusReporter reporter,
RawComparator<KEYIN> comparator,
Class<KEYIN> keyClass,
Class<VALUEIN> valueClass
) throws IOException, InterruptedException {
super(conf, taskid, input, inputKeyCounter, inputValueCounter,
output, committer, reporter, comparator, keyClass, valueClass);
}
}
protected void setup(Context context) throws IOException, InterruptedException {
// NOTHING
}
protected void reduce(KEYIN key, Iterable<VALUEIN> value, Context context)
throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
protected void cleanup(Context context) throws IOException, InterruptedException {
// NOTHING
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try{
while(context.nextKeyValue()) {
reduce(context.getCurrentKey(), context.getValues(), context);
}
}finally{
cleanup(context);
}
}
}
- Mapper와 상속하는 클래스만 다르고 나머지는 같습니다.
InputFormat & OutputFormat
- 맵리듀스는 입력 스플릿을 맵 메서드의 입력 파라미터로 사용할 수 있게 InputFormat이라는 추상 클래스를 제공합니다.
- 기본값은 개행문자(\n)를 기준으로 레코드를 분류하는 `TextInputFormat`을 사용합니다.
- 맵리듀스 잡의 출력 데이터 포멧은 OutputFormat이라는 추상 클래스를 상속받아 구현됩니다.
- 기본값은, 레코드를 출력할 때 키와 값의 구분자를 텝을 사용하는 `TextOutputFormat`을 사용합니다.
이상 하둡의 첫 포스트를 마치도록 하겠습니다. 다음 포스트는 책에 있는 내용을 요약해서 정리하도록 하겠습니다.
WordCount 만들기
Mapper 구현
- 입력 key = 라인 번호, 입력 value = 문장
- 출력 key = 글자, 출력 value = 글자 수
public class WordCount {
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
- 상속 Mapper<LongWritable, Text, Text, IntWritable> <=> (입력 키, 입력 값, 출력 키, 출력 값)
- Map class에서 final static 변수로 선언한 one은 값이 1인 Integer입니다.
- map 함수 재정의 => map(LongWritable key, Text value, Context context)
- value를 String으로 변환하고(toString) 공백(space) 단위로 구분하기 위해 StringTokenizer 객체를 선언합니다.
- String 값을 순회하면서 (key-word, value-one)인 레코드를 추가합니다.
Reducer 구현
- mapper의 출력을 Reducer의 입력으로 받습니다.
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
- 상속 Reducer<Text,IntWritable,Text,IntWritable> <=> (입력 키, 입력 값, 출력 키, 출력 값)
- reduce 함수 재정의 => reduce(Text key, Iterable<IntWritable> values, Context context)
- map이랑 비슷한데, 차이점은 Iterator로 감싼다는 것입니다.
- 중복된 key의 개수를 구하기 위해 for문 사용해서 sum 변수에 value(one)를 계속 더합니다.
Driver 구현
- mapper & reducer class를 실행하는 것이 driver class.
- job 객체 생성 -> 맵리듀스 job의 실행 정보 설정 -> 맵리듀스 job 실행
``` java
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionParser.getRemainingArgs();
if ((remainingArgs.length != 2) && (remainingArgs.length != 4)) {
System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class)job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs.get(0)));
FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1)));
job.waitForCompletion(true);
}
```
WordCount 빌드
- 모든 클래스를 구현했으면, 컴파일을 해서 jar 파일을 만듭니다.
- 이클립스 or 인텔리제이 or ubuntu에서 maven 사용 등 각자 편하신데로 jar 파일을 만들어줍니다.
maven 설치
- 저같은 경우는 리눅스 환경에서 maven 사용해서 jar 파일을 만들었습니다.
- maven 설치 및 `Unable to locate package maven` 오류 해결법 - [출처] ubuntu 18.04에서 apt install maven이 안될때|작성자 Fiver
```
sudo apt-get install software-properties-common
sudo apt-add-repository universe
sudo apt-get update
sudo apt-get install maven
```
pom.xml 설정
- maven 설치 후 pom.xml 파일을 만들어서 의존성 관리를 해주어야 합니다.
- 제 환경에서는 하둡 버전이 3.2.1 이기 때문에 각자의 version에 맞춰서 바꿔주시면 됩니다.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.hadoop.mapreduce-example</groupId>
<artifactId>wordcount-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
</project>
jar 생성
- wordcount.java 파일과 pom.xml을 같은 경로에 두고, `mvn clean install`을 입력해줍니다.
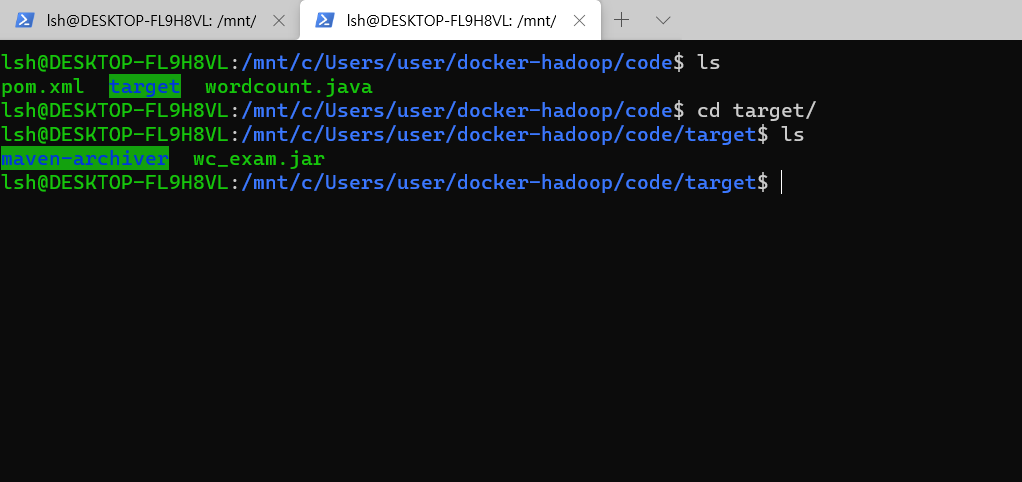
- 빌드가 완료되면 target이라는 디렉토리가 생기고 안으로 들어가면, OOOOO.jar 파일이 생성됩니다.
- 이 jar 파일을 namenode에 옮겨줍니다. `docker cp wc_exam.jar namenode:/tmp/`
wordcount 실행
- input으로 쓰일 txt 파일이 hdfs input 디렉토리에 이미 준비되어있다고 가정합니다.
- `hadoop jar wc_exam.jar org.apache.hadoop.examples.WordCount input output/test_0`
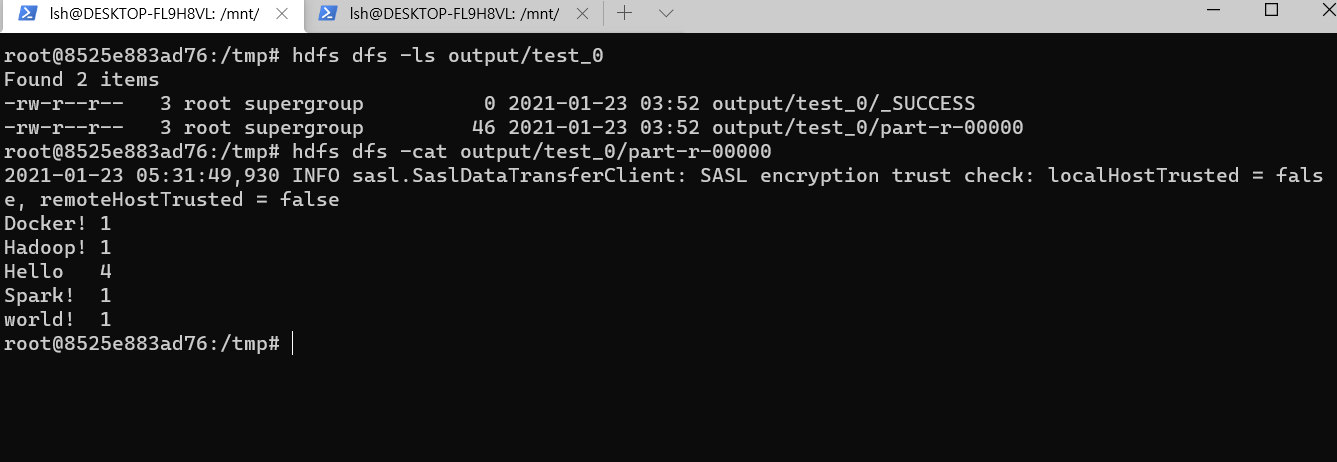
- 결과를 hdfs에 들어가서 조회할 수 있습니다.
Reference
- 시작하세요 하둡 프로그래밍
- Medialog-Hadoop.
- Apache Hadoop.
- cloudera Hadoop.
- wordcount code.
